Why I built yet another dependency graph scanner
I know, another dependency scanner. But here's the design bet behind Bomly: one resolved dependency graph powering SBOMs, vulnerability and license audits, package explanations, and Git-ref diffs — from your terminal to CI to agents.
I'll say it before you do: the world isn't short on dependency scanners. So why build another one?
Because most of the interesting questions about a codebase's dependencies have the same shape:
- What's actually in this tree — all the way down, and in what scope?
- Why is this package here — who pulled it in?
- Does anything here carry a known vulnerability or a license we can't ship?
- Did this change add new risk, or is it debt we already had?
They look like four different tools' worth of questions. They're really four views of one thing: a resolved dependency graph. Build that graph once, keep it as a real, first-class object, and SBOMs, audits, explanations, and diffs all fall out of the same model instead of four separate tools. The other half of the design is where you get to ask — on your own machine, in CI, and inside a pull request, with any network calls opt-in and on your terms.
That combination is the whole reason Bomly exists. What follows is a walk through the design choices behind it — most of which are worth thinking about whether or not you ever install the thing.
One graph, many workflows
A lot of the richest dependency tooling has historically lived behind paid platforms or hosted dashboards. What I kept wanting was to see how much of that day-to-day workflow could live in a small, free, open tool that runs right next to your code, with nothing to log into.
So Bomly is built around a single pipeline that resolves one graph, and a set of consumers that render views of it. Roughly, it discovers the ecosystems in your project, runs the right detector for each, optionally enriches the packages with outside data, audits the result, and formats the output. The part that matters is what happens once the graph exists: SBOM export, the vulnerability and license audit, explain, and diff all read the same in-memory model — manifests, packages keyed by PURL, findings keyed by reference — instead of re-parsing the tree. That's not just tidy internally; it's why the SBOM and the SARIF report always describe the same packages. They came from the same place.
What Bomly scans
Your dependencies don't only change on the default branch. They change on the feature branch you're about to open a PR for, in a container you're about to ship, in an SBOM a vendor just handed you. So the graph is deliberately indifferent to where it came from:
- Projects — point it at a source tree and it discovers every recognized lockfile or manifest and runs the right detector chain per subproject, across 30+ ecosystems.
- SBOMs — read an existing SPDX or CycloneDX document as the graph source. Bomly both produces and consumes the major SBOM formats, so it fits into a pipeline that already has one.
- Containers — scan an image with
--image. Container scanning is powered by Syft, so you get a solid package inventory, but without the transitive relationships and scope information Bomly resolves for source projects. - Git refs — scan a repository at a ref via
--url/--ref, without cloning it by hand.
bomly scan
bomly scan --image ghcr.io/your-org/your-app:latest
Detectors differ in how they work, and I try to be upfront about it. Some parse lockfiles fully offline; others shell out to the real build tool (Go, Maven, Gradle, sbt) because that's the honest way to resolve those ecosystems — which means those detectors can reach a package registry even without enrichment. I'd rather name that seam than paper over it.
How the graph gets used
SBOMs are a serialization step, not a second scan. Because the graph is already a package set with relationships, emitting SPDX 2.3 or CycloneDX 1.6 is nearly free:
bomly scan -o spdx=sbom.spdx.json \
-o cyclonedx=sbom.cdx.json # multiple files, one pass
Relationships and scope are kept, not flattened. A flat list of packages tells you what you have. The graph also keeps how each package got there and which scope it lives in — runtime versus dev. That's the difference between a wall of findings and a prioritized one: a critical advisory in a transitive runtime dependency is a very different Tuesday than the same advisory in a dev-only dependency.
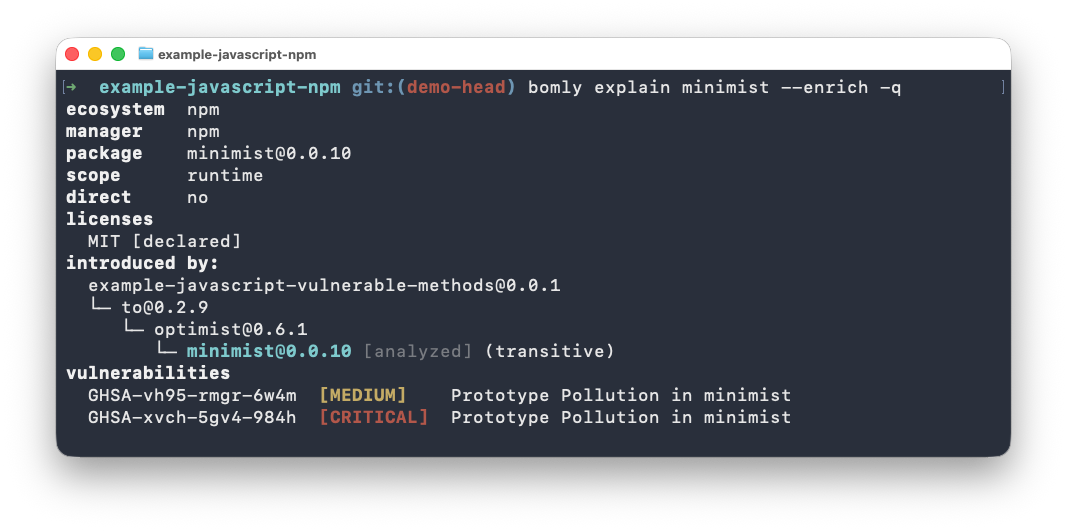
Explain answers "why is this even here?" It's a shortest-path query over the graph:
bomly explain minimist
You get the path that introduced the package, plus alternative paths when there are several roots.
Diffs separate new risk from old debt. Bomly resolves the graph at two refs and sorts findings into three buckets — introduced (new at head), resolved (gone at head), and persisted (present in both):
bomly diff --base main --head HEAD --enrich --audit
Diff-based gating leans on that split: it focuses on new risk, so a change that introduces nothing can pass even when the repo carries pre-existing findings, and you review what the PR actually adds instead of re-litigating history. Findings are matched per package version, though, so a known advisory that rides in on a version bump still counts as newly introduced — a version change is a change.
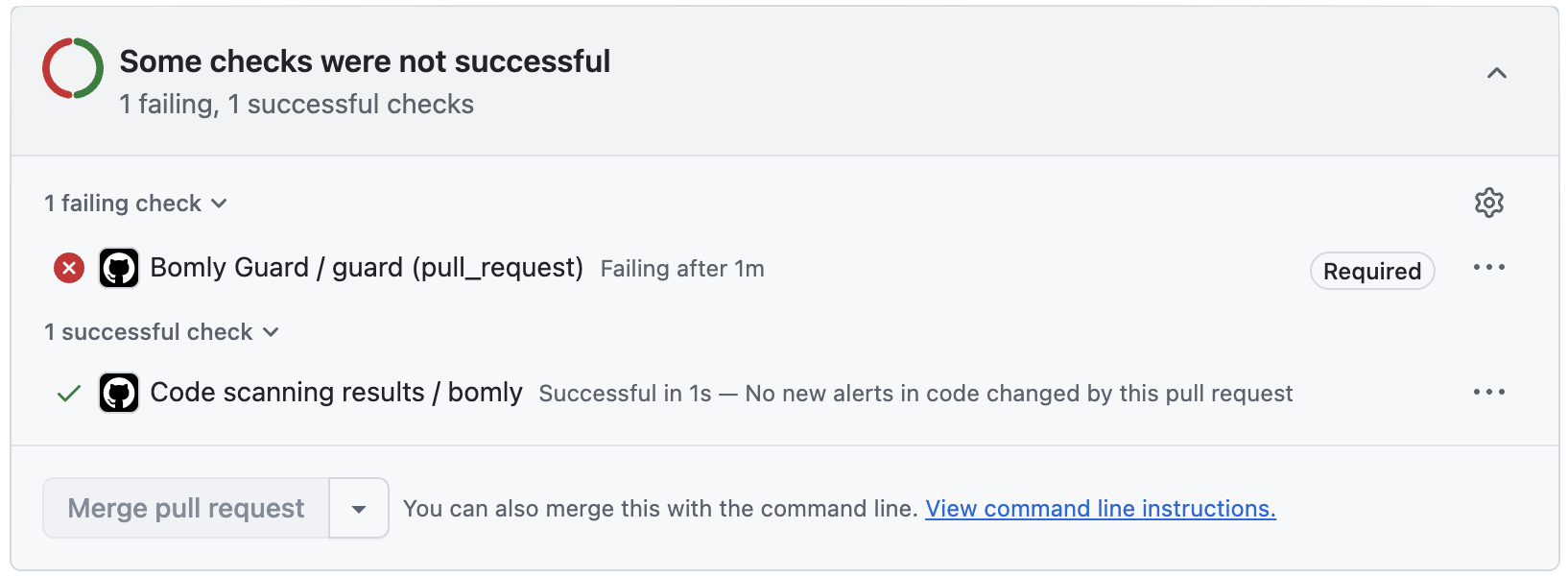
CI output speaks the formats you already ingest. The audit view serializes to SARIF 2.1.0, plus JSON, Markdown, and text. On GitHub repos with code scanning enabled, Bomly Guard — the Action wrapper around bomly diff — can point at the exact line that introduced a finding, right there in the pull request. The policy you test locally with --fail-on is the same policy Guard enforces; there's no second policy language to keep in sync.
Enrichment is opt-in, and that's a trust decision
This is a design choice I care about. Setting aside the build-tool detectors above — which may talk to a package registry to resolve a graph — Bomly's built-in matchers and auditors don't reach out on their own. Enrichment is the one place the built-ins deliberately make external calls, and only when you ask for it, with --enrich:
bomly scan --enrich --audit
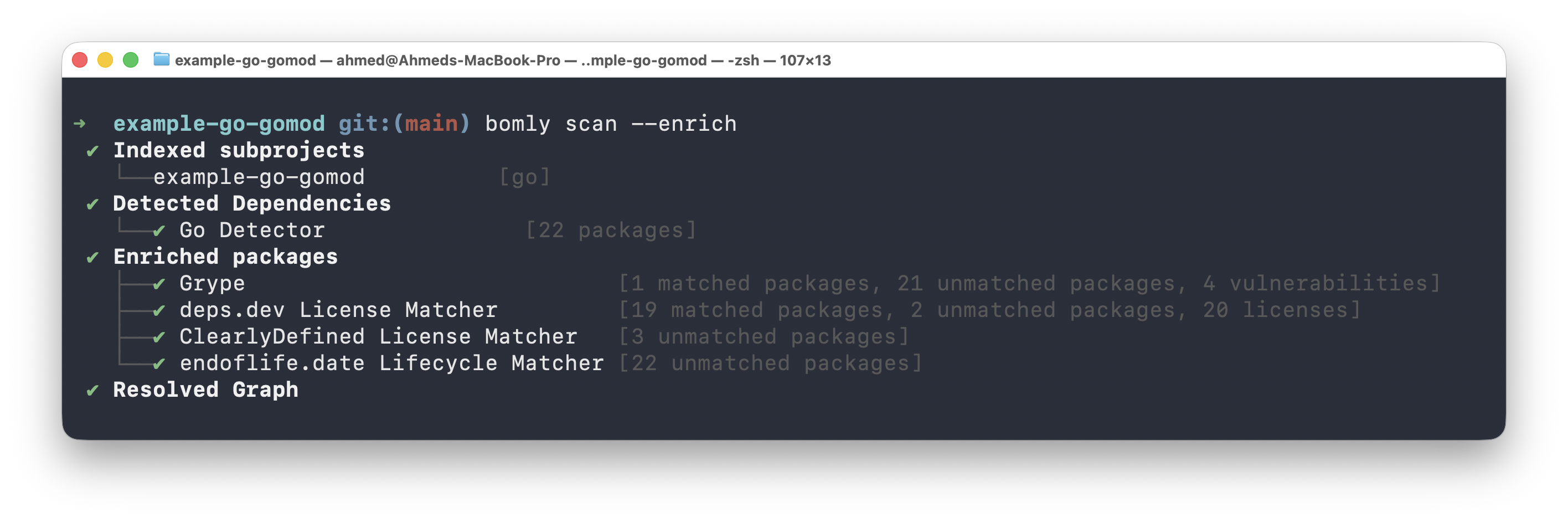
Those calls go to a fixed, documented set of public sources for advisory, license, lifecycle, and scorecard data, and the components that can cache their responses do, so repeat runs stay quick. Two reasons I like this shape:
- You should know when a network call happens. For a security tool, "which servers did this contact, and when" isn't a footnote — it's part of the trust model, so I'd rather the trigger be explicit and the calls be predictable.
- Auditing the built-ins stays local. Evaluating findings against the built-in policy doesn't quietly kick off fresh fetches behind your back.
I'll be precise, though: nothing here blocks traffic. A plugin can make outbound calls by design — a matcher enriching against your internal advisory feed is supposed to, and an auditor could pull rules from a source you point it at. The promise isn't "Bomly never touches the network." It's that the built-ins are predictable about when they do, and that turning enrichment on is your call.
Extensible on purpose
I didn't want Bomly to be a closed list of what I happen to have implemented, or a place you get locked into. The plugin system is the part I'm most excited to grow with other people. Plugins are Go binaries built against the public sdk package, and there are three kinds you can write:
- a detector plugin to teach Bomly an internal manifest format or an ecosystem the core doesn't cover yet,
- a matcher plugin to enrich packages against your own private advisory or metadata feed,
- an auditor plugin to encode the rules and thresholds your organization actually cares about.
bomly plugins install github.com/your-org/your-plugin@latest
bomly plugins enable your-plugin
That turns "Bomly doesn't support my thing" from a dead end into an afternoon. If your ecosystem, your feed, or your policy is unusual, you don't have to wait on me — and you don't have to fork the binary.
Built for a world with more agents in it
More and more code is going to be written with AI agents somewhere in the loop, and those agents keep needing the same dependency answers we do. Bomly runs an MCP server so an agent can ask directly and get the same structured, deterministic result the CLI produces — no screen-scraping, no parsing a wall of text, no guessing:
bomly mcp serve
It's one integration point among several, not the center of the design — but a scanner that returns the same answer to a human and to an agent feels like the right shape for where things are heading.
How it's built (and how to judge it)
Bomly is built with a lot of help from AI, and I'm not shy about saying so. But it isn't vibe-coded. I'm in the loop the whole way — steering and redirecting as the work takes shape — and every change goes through review by multiple models playing different roles and critiquing each other, before a final human review pass from me. Under all of it sits a broad smoke-test suite and a benchmark command built into the tool for measuring dependency-graph resolution against real repositories.
I'd genuinely rather you evaluate Bomly by its code, tests, docs, and honest limitations than by any adjective I could put in front of it. How the built-ins handle the network, the enrichment endpoint list, the diff classification — they're all things you can read in the source and check. A security tool should be checkable, not taken on faith.
Where it's honest about its limits
A tool that isn't loud about its edges is doing you a quiet disservice, so:
- It's early. APIs, output shapes, and defaults can still move.
- Ecosystem coverage varies. Some detectors parse lockfiles directly; others lean on the build tool. Depth and precision differ, and not everything is covered yet.
- Reachability is experimental and uneven. By default Bomly answers "is this vulnerable package present," not "does your code call the vulnerable function" — that's package-level, not symbol-level. An experimental reachability stage goes deeper in some languages than others, but "not flagged reachable" still isn't the same as "safe."
- Enrichment is only as good as its sources. Vulnerability and license data come from public feeds; gaps upstream become gaps in the output.
None of these are dealbreakers. They're the boundary conditions that let you use the output responsibly.
Try it, and tell me where it's wrong
go install github.com/bomly-dev/bomly-cli/cmd/bomly@latest
bomly scan
For Homebrew, WinGet, Scoop, install scripts, and packaged releases, see the installation guide. The getting-started guide goes from install to your first enriched scan in a few minutes.
Bomly is completely free and open source under Apache-2.0 — all of it, for anyone to use, fork, and build on. And it's early, which is exactly when a bit of community help changes the trajectory the most. The genuinely useful next steps:
- Try it on a real project and see if the graph tells you something you didn't know
- Star the repo if you'd like to follow along
- Start a discussion with feedback, rough edges, or a workflow you wish it supported
- Open an issue for a bug or a gap
- Write a plugin for the ecosystem, feed, or policy you wish it understood
If you try it and something is unclear, wrong, or missing, I'd love to hear it — that feedback is the most valuable thing this project can get right now.